



Microsoft Fabric is a comprehensive data analytics platform that offers advanced data science capabilities. It allows users to go through the entire analytics process – from initial data exploration and preparation, through model development, experimentation, and finally obtaining valuable business insights.
Data Science in Microsoft Fabric – what is it?
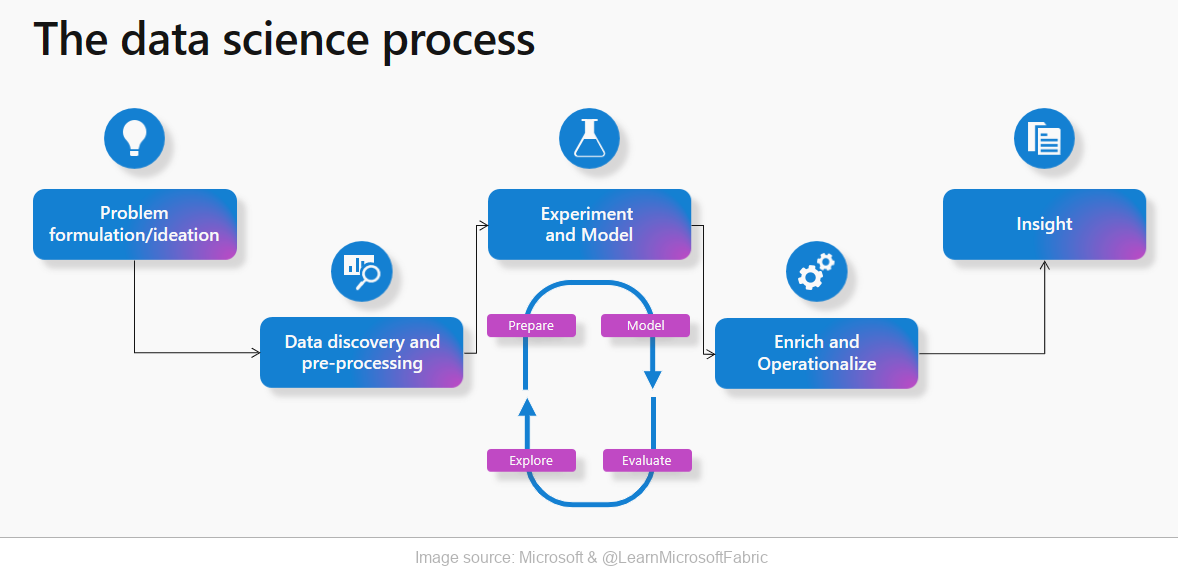
Data Science in Microsoft Fabric is a well-defined process that is used in most machine learning projects. Here are the key steps:
- Problem formulation and idea generation – this stage involves defining the problem and identifying the expected results.
- Data discovery and processing – this step involves exploring and preparing data for analysis.
- Experimenting and modeling – building and training machine learning models.
- Enrichment and operationalization – integration of the model with production work processes.
- Formulating conclusions – using model predictions to obtain valuable business information.
Microsoft Fabric – support at every stage of Data Science
Microsoft Fabric offers tools, services, and objects that integrate seamlessly with every step of the Data Science process. Below, we take a closer look at how this process works.
Formulating problems and generating ideas
Data scientists, business users, and analysts can work on the same platform, facilitating seamless data sharing and collaboration. Power BI reports and datasets can be easily shared across teams, facilitating effective information transfer when formulating problems.
Data discovery and processing
OneLake and Lakehouse – users can work with data stored in Lakehouse in OneLake in direct connection with Notebook. This allows for easy exploration and browsing of data.
Seamless data reads – data can be seamlessly read from Lakehouse into Pandas DataFrame for easy exploration.
Pipelines and Data Integration – Microsoft Fabric offers a set of built-in tools for creating powerful data integration pipelines. These pipelines can be easily built to obtain and transform data for use in machine learning models.
Data Exploration with Notebooks – Notebooks are a quick and convenient way to start exploring your data, regardless of where it is stored.
Apache Spark and Python – Fabric offers the ability to process, prepare, and explore data at scale. Tools like PySpark/Python, Scala, and SparkR/SparklyR enable large-scale data processing.
Data Wrangler for data cleansing – Data Wrangler accelerates and automates data cleansing by generating Python code to speed up tedious tasks.
Experimentation and modeling of machine learning
Machine Learning (ML) Tools – Notebooks can leverage tools like PySpark/Python, SparklyR/R to train machine learning models.
Library Management – users can install a variety of popular machine learning libraries as per their model training needs.
Scikit Learn Integration – the popular Scikit Learn library can also be used to create models.
MLflow to track ML model training – experiments can be tracked within the built-in MLflow environment provided by Microsoft Fabric.
Enrichment and operationalization
Batch scoring – Fabric Notebooks can support batch scoring of machine learning models using open-source libraries or Microsoft Fabric’s scalable Spark Predict feature, which supports models wrapped in MLflow in a model registry.
Formulating conclusions
Power BI Integration – predicted values can be easily saved in OneLake and seamlessly used in Power BI reports, thanks to Power BI Direct Lake mode. This simplifies operationalization and enables Data Science professionals to easily share results with stakeholders.
Notebooks Scheduling – batch scoring Notebooks can be run at specified intervals using the Notebooks scheduling feature in Fabric. Batch scoring can also be integrated with Spark jobs or data pipelines. Power BI automatically pulls the latest forecasts, eliminating the need to load or refresh data with Direct Lake mode.
Semantic link (preview)
Data scientists and business analysts often spend a lot of time cleaning, transforming, and understanding data before they can perform any analysis. In their day-to-day work, business analysts implement expert knowledge and business rules into semantic models, which are then used to create measures in Power BI. A data scientist, on the other hand, may work with the same data but in a different language or coding environment.
Semantic Link (preview) solves this problem by enabling Data Scientists to establish a connection between Power BI semantic models and the Synapse Data Science environment using a Python library called SemPy. It simplifies data analysis by enabling the use of data semantics while transforming semantic models. This enables Data Scientists to:
- avoid re-implementation – reduce the need to re-create business logic and domain knowledge in Data Science code in Microsoft Fabric,
- leverage Power BI metrics – easily access and leverage Power BI metrics directly in your Data Science workflows,
- discover new possibilities – use semantics to power innovative experiences, such as semantic features,
- improve data understanding – explore and verify functional dependencies and relationships in data.
Data Science in Microsoft Fabric and the benefits for your organization
By using SemPy and Semantic Link, your organization can benefit from:
- increased productivity – faster collaboration and improved efficiency between teams working on the same data sets,
- better cross-team collaboration – stronger collaboration between Business Intelligence and AI teams,
- reduced implementation time – a smoother learning curve for new team members working with existing models and datasets.
Summary
Microsoft Fabric is a comprehensive platform that allows data scientists to flourish. It provides an integrated environment for data exploration, preparation, modeling, and deployment, enabling organizations to maximize the potential of their data. Integration of tools such as Notebooks, Data Wrangler, and SynapseML, combined with the ability to leverage knowledge from Power BI, creates a powerful ecosystem for data-driven decision-making.
If you need help implementing Fabric in your company, we’re here to help! – Contact us and we’ll answer your questions!