



Microsoft Fabric to kompleksowa platforma do analizy danych, która oferuje zaawansowane możliwości w zakresie Data Science. Dzięki niej użytkownicy mogą przejść przez cały proces analityczny – od wstępnego badania i przygotowania danych, poprzez rozwój modeli, eksperymentowanie, aż po uzyskiwanie cennych informacji biznesowych.
Data Science w Microsoft Fabric – co to jest?
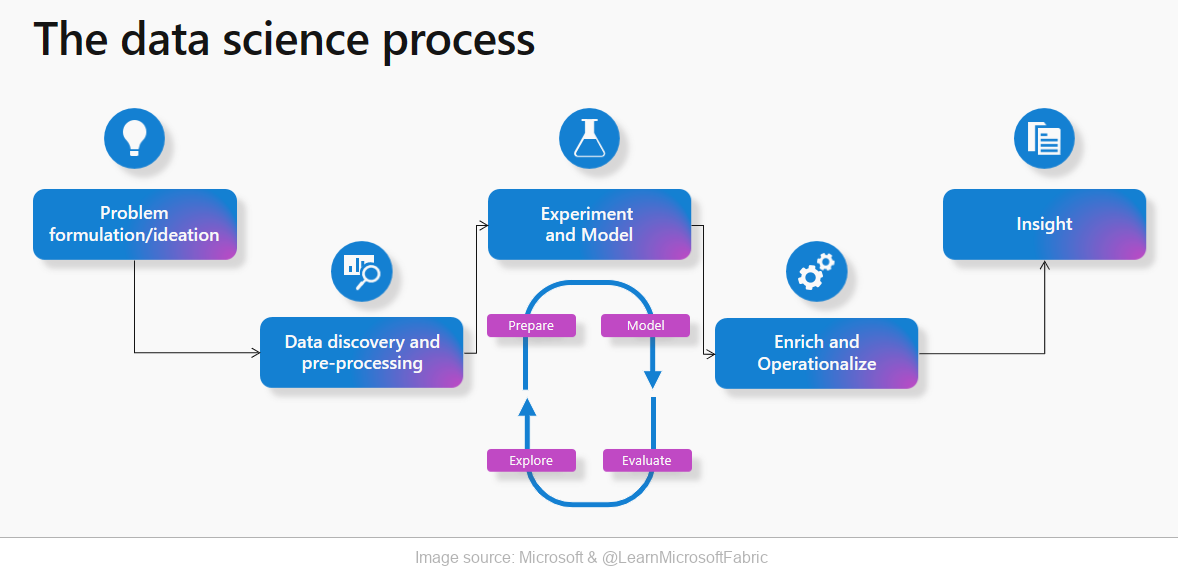
Data Science w Microsoft Fabric to dobrze zdefiniowany proces, który stosuje się w większości projektów związanych z uczeniem maszynowym. Oto jego kluczowe etapy:
- Formułowanie problemów i generowanie pomysłów – na tym etapie definiuje się problem i identyfikuje oczekiwane rezultaty.
- Odkrywanie i przetwarzanie danych – w tym kroku odbywa się eksploracja i przygotowanie danych do analizy.
- Eksperymentowanie i modelowanie – budowanie i trenowanie modeli uczenia maszynowego.
- Wzbogacanie i operacjonalizacja – integracja modelu z produkcyjnymi procesami roboczymi.
- Formułowanie wniosków – wykorzystanie prognoz modelu do uzyskania cennych informacji biznesowych.
Microsoft Fabric – wsparcie na każdym etapie Data Science
Microsoft Fabric oferuje narzędzia, usługi i obiekty, które płynnie integrują się z każdym etapem procesu Data Science. Poniżej przyjrzymy się bliżej przebiegowi tej procedury.
Formułowanie problemów i generowanie pomysłów
Specjaliści Data Science, użytkownicy biznesowi i analitycy mogą pracować na tej samej platformie, co ułatwia płynne dzielenie się danymi i współpracę. Raporty i zestawy danych Power BI mogą być łatwo udostępniane między zespołami, co ułatwia efektywne przekazywanie informacji podczas formułowania problemów.
Odkrywanie i przetwarzanie danych
OneLake i Lakehouse – użytkownicy mogą pracować z danymi przechowywanymi w Lakehouse w OneLake w bezpośrednim połączeniu z Notebook. Umożliwia to łatwą eksplorację i przeglądanie danych.
Płynne odczyty danych – dane mogą być bezproblemowo odczytywane z Lakehouse do Pandas DataFrame, co ułatwia ich eksplorację.
Pipeline’y i integracja danych – Microsoft Fabric oferuje zestaw wbudowanych narzędzi do tworzenia potężnych pipeline’ów integracji danych. Pipeline’y te można łatwo zbudować, aby uzyskać i przekształcić dane do wykorzystania w modelach uczenia maszynowego.
Eksploracja danych z Notebooks – notatniki to szybki i wygodny sposób na rozpoczęcie eksploracji danych, niezależnie od miejsca ich przechowywania.
Apache Spark i Python – Fabric oferuje możliwości przetwarzania, przygotowania i eksploracji danych na dużą skalę. Narzędzia takie jak PySpark/Python, Scala oraz SparkR/SparklyR umożliwiają przetwarzanie danych na dużą skalę.
Data Wrangler do czyszczenia danych – Data Wrangler przyspiesza i automatyzuje czyszczenie danych, generując kod Python do przyspieszania wykonywania nużących zadań.
Eksperymentowanie i modelowanie uczenia maszynowego
Narzędzia Machine Learning (ML) – Notebooks mogą wykorzystywać narzędzia takie jak PySpark/Python, SparklyR/R do trenowania modeli uczenia maszynowego.
Zarządzanie bibliotekami – użytkownicy mogą instalować różnorodne popularne biblioteki uczenia maszynowego, zgodnie z potrzebami w zakresie trenowania modeli.
Integracja z Scikit Learn – Popularna biblioteka Scikit Learn może być również używana do tworzenia modeli.
MLflow do prześledzenia szkolenia modelu ML – eksperymenty mogą być śledzone w ramach wbudowanego środowiska MLflow oferowanego przez Microsoft Fabric.
Wzbogacanie i operacjonalizacja
Batch scoring – notatniki Fabric mogą obsługiwać batch scoring modeli uczenia maszynowego za pomocą bibliotek open-source lub skalowalnej funkcji Spark Predict w Microsoft Fabric, która wspiera modele zapakowane w MLflow w rejestrze modeli.
Formułowanie wniosków
Integracja z Power BI – prognozowane wartości (Predicted values) można łatwo zapisać w OneLake i bezproblemowo wykorzystywać w raportach Power BI, dzięki trybowi Power BI Direct Lake. To upraszcza operacjonalizację i umożliwia specjalistom Data Science łatwe dzielenie się wynikami z interesariuszami.
Planowanie w Notebooks – notatniki zawierające batch scoring można uruchamiać w określonych odstępach czasowych przy wykorzystaniu funkcji planowania w Notebooks w Fabric. Batch scoring można również zintegrować z zadaniami Spark lub pipeline’ami danych. Power BI automatycznie pobiera najnowsze prognozy, eliminując potrzebę ładowania lub odświeżania danych dzięki trybowi Direct Lake.
Semantic link (w wersji preview)
Specjaliści Data Science i analitycy biznesowi często spędzają dużo czasu na czyszczeniu, przekształcaniu i zrozumieniu danych, zanim rozpoczną jakiekolwiek analizy. W swojej codziennej pracy analitycy biznesowi implementują wiedzę ekspercką i reguły biznesowe w modelach semantycznych, które następnie są wykorzystywane do tworzenia miar w narzędziu Power BI. Z kolei Data Scientist może pracować z tymi samymi danymi, ale w innym języku lub środowisku kodowania.
Semantic link (wersja preview) rozwiązuje ten problem, umożliwiając specjalistom Data Science ustanowienie połączenia między modelami semantycznymi Power BI a środowiskiem Synapse Data Science za pomocą biblioteki Python o nazwie SemPy. Upraszcza ona analizę danych, umożliwiając korzystanie z semantyki danych podczas przekształcania modeli semantycznych. Dzięki temu Data Scientist może:
- uniknąć ponownej implementacji – zmniejszyć potrzebę ponownego tworzenia logiki biznesowej i wiedzy domenowej w kodzie Data Science w Microsoft Fabric,
- wykorzystać miary Power BI – łatwo uzyskać dostęp do miar Power BI i wykorzystać je bezpośrednio w przepływach pracy Data Science,
- odkrywać nowe możliwości – wykorzystać semantykę do zasilania innowacyjnych doświadczeń, takich jak funkcje semantyczne,
- poprawić zrozumienie danych – badać i weryfikować funkcjonalne zależności i relacje w danych.
Data Science w Microsoft Fabric a korzyści dla Twojej organizacji
Wykorzystując SemPy i Semantic Link, Twoja organizacja może zyskać na:
- zwiększonej produktywności – szybszej współpracy i poprawy efektywności między zespołami pracującymi na tych samych zestawach danych,
- lepszej współpracy międzyzespołowej – silniejszej współpracy między zespołami zajmującymi się Business Intelligence i AI,
- skróceniu czasu wdrażania – łagodniejszej krzywej uczenia dla nowych członków zespołu pracujących z istniejącymi modelami i zestawami danych.
Podsumowanie
Microsoft Fabric to wszechstronna platforma, która pozwala specjalistom Data Science na rozwinięcie skrzydeł. Zapewnia zintegrowane środowisko do eksploracji, przygotowania, modelowania i wdrażania danych, co umożliwia organizacjom maksymalne wykorzystanie potencjału ich danych. Integracja narzędzi takich jak Notebooks, Data Wrangler i SynapseML, w połączeniu z możliwością korzystania z wiedzy z Power BI, tworzy potężny ekosystem do podejmowania decyzji opartych na danych.
Jeżeli potrzebujesz pomocy we wdrożeniu Fabric w Twojej firmie, służymy pomocą! – Skontaktuj się z nami, a odpowiemy na Twoje pytania!